Web Crawler
Java-based Search Engine Project • Mar 2024 - May 2024
Project Overview
COMP4321-Crawler is a web crawler and search engine project developed for the COMP4321 Information Retrieval course. It focuses on building a functional search engine with a spider for web crawling, an indexer for keyword extraction, and a retrieval function that ranks results based on relevance.
Key Features
- Spider Function - Recursively fetches pages from a given website using BFS algorithm
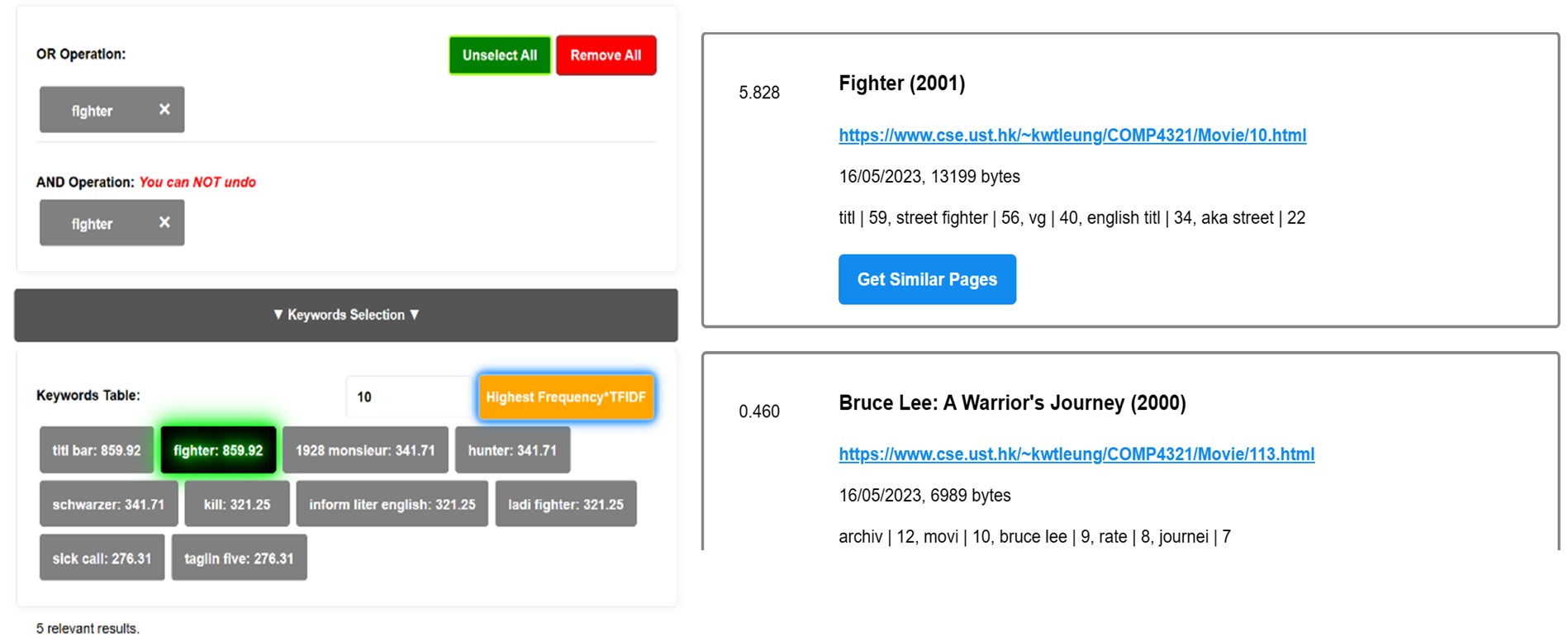
- Indexer - Extracts keywords from pages and inserts them into an inverted file structure
- Retrieval Function - Compares query terms against the inverted file and returns top-ranked documents
- Phrase Query Support - Advanced search capabilities with phrase matching
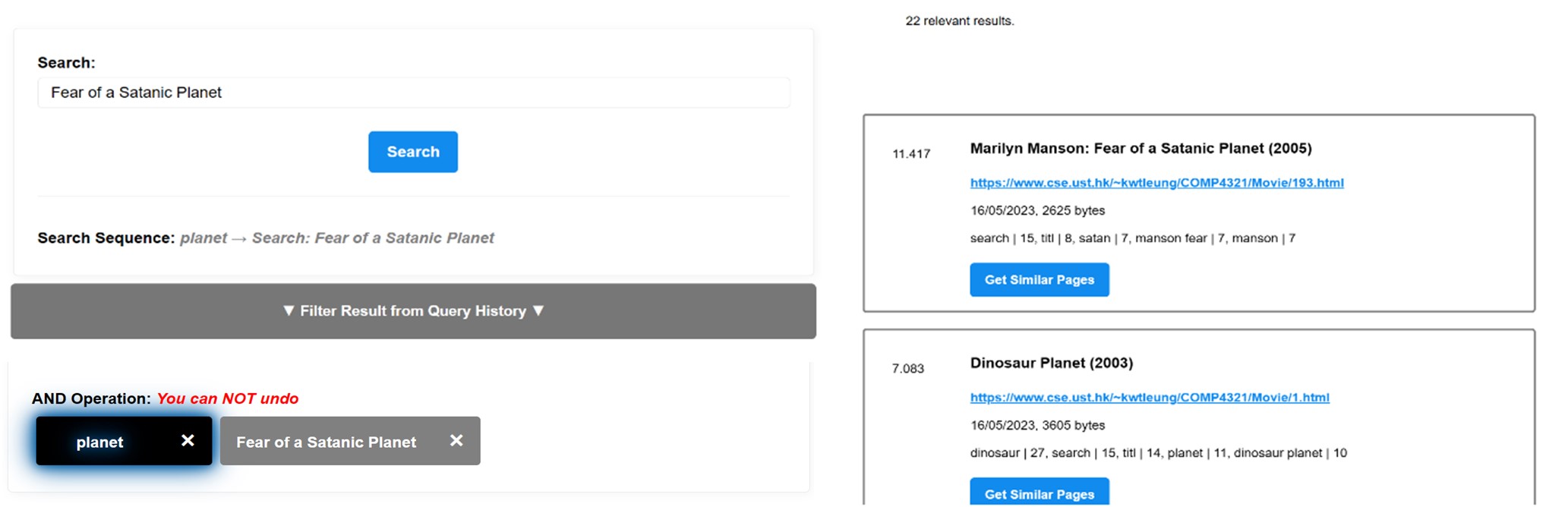
- Web Interface - User-friendly interface for query input and result display
System Architecture
Backend Components
- Crawler with Breadth-First Search (BFS) implementation
- Text processing pipeline (stop word removal, stemming)
- N-gram extraction for enhanced search capabilities
- JDBM database for efficient data storage and retrieval
Frontend Interface
- Clean, intuitive search interface
- Vector space model with cosine similarity ranking
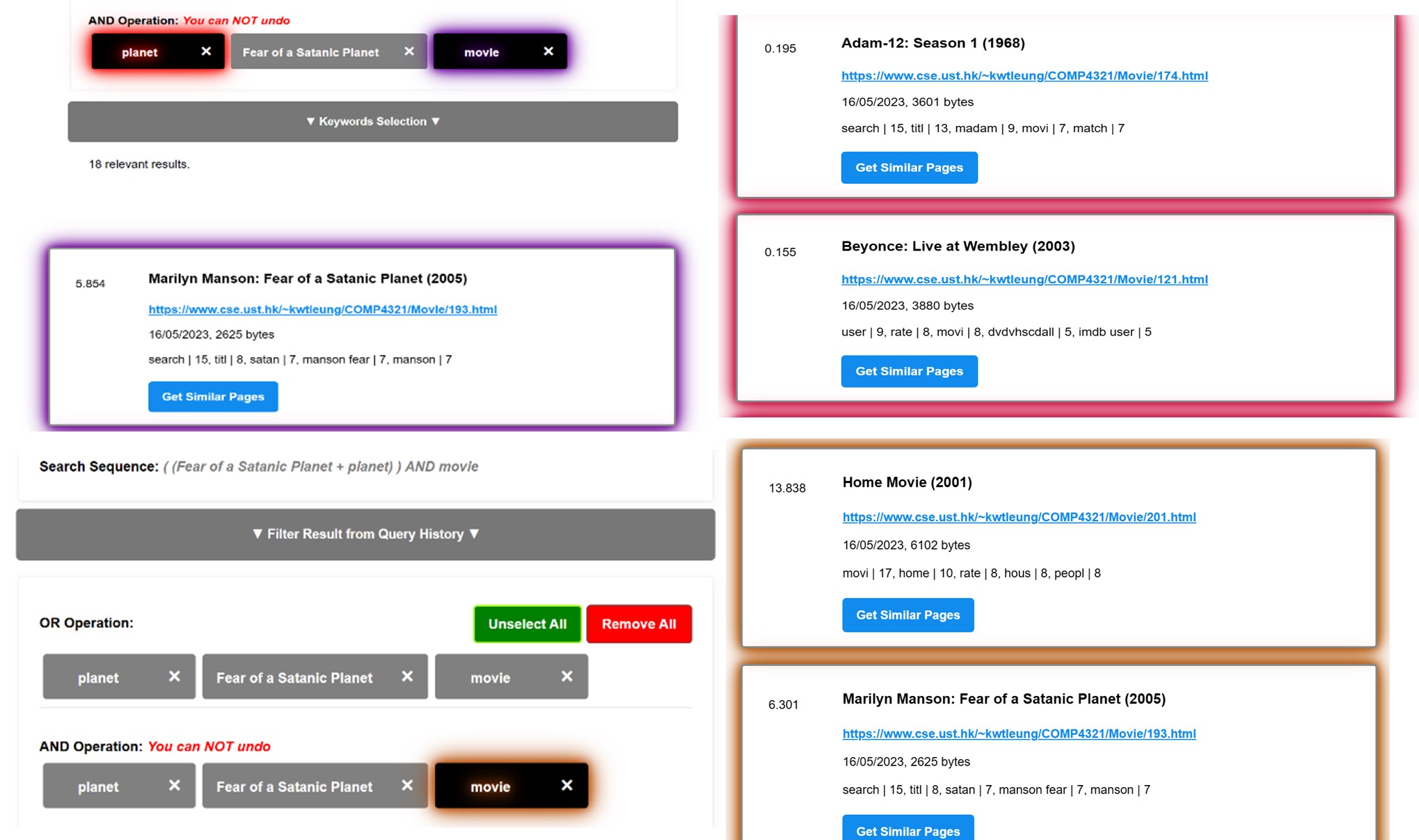
- Advanced search with AND/OR operators
- Comprehensive result display with relevance scoring
Technology Stack
Programming Language:
Java (OpenJDK 21.0.2)
Web Server:
Apache Tomcat
Database:
JDBM
Algorithms:
BFS
Vector Space Model
Cosine Similarity
System Screenshots
Search Results Interface
Advanced Search with Boolean Operators
Keyword Analysis Table
Project Links & Information
Repository
Find the source code and additional information in the COMP4321-Crawler GitHub repository:
View on GitHubLicense
This project is open-source and available under the MIT License.